As software developers, you interact with databases almost daily, but almost never (and probably will never) create a database yourself. There are tons of databases available today (e.g., Postgres, MongoDB, VoltDb, Redis, etc) but to deliver performant and manageable applications you need to pick which one of them is best suited as per your requirements, to evaluate different choices you will need to know the internals on how they operate and store data.
In this series, we will focus on storage engines of databases and how the usage of different data structures determines their characteristics. We will explore real-world implementations of various data structures used in production databases, their benefits, and challenges
Database
The only use of a database is to store data and retrieve it when queried.
You can create a simple key-value csv database(a type of log-structured database as it stores data as a log of all update operation), in a few lines of python (csvdb.py).
To insert and update
Append at bottom of file
To retrieve
Find first matching entry from bottom
db_filename="db.csv"
def set_key(key, value):
with open(db_filename,'a') as db:
db.write("{},{}\n".format(key, value))
def get_key(key):
with open(db_filename,'r') as db:
for entry in reversed(db.readlines()):
if key_in_entry(key, entry):
return get_value(entry)
raise Exception('key not found')
def key_in_entry(key, entry):
kv = entry.split(",")
return str(key) == kv[0]
def get_value(entry):
kv = entry.split(",")
return kv[1].strip()
Run python where csvdb.py is located and follow
Python 2.7.10 (default, Oct 6 2017, 22:29:07)
>>> from csvdb import *
>>> set_key('foo', 'bar')
>>> get_key('foo')
'bar'
>>> set_key('foo', 'nada')
>>> get_key('foo')
'nada'
It is definately not the most optimised database, but good for our purpose.
Pros - Fast inserts and updates O(1)
Cons - Slow read Speed, requires a sequential scan to get value O(n)
To make the reads faster some databases use Hash Index.
Hash Index
Hash Index is In-Memory data-structure (Hash map implementation provided by common programming languages) maintained alongside the main database file which stores the offset of a key in the database file.
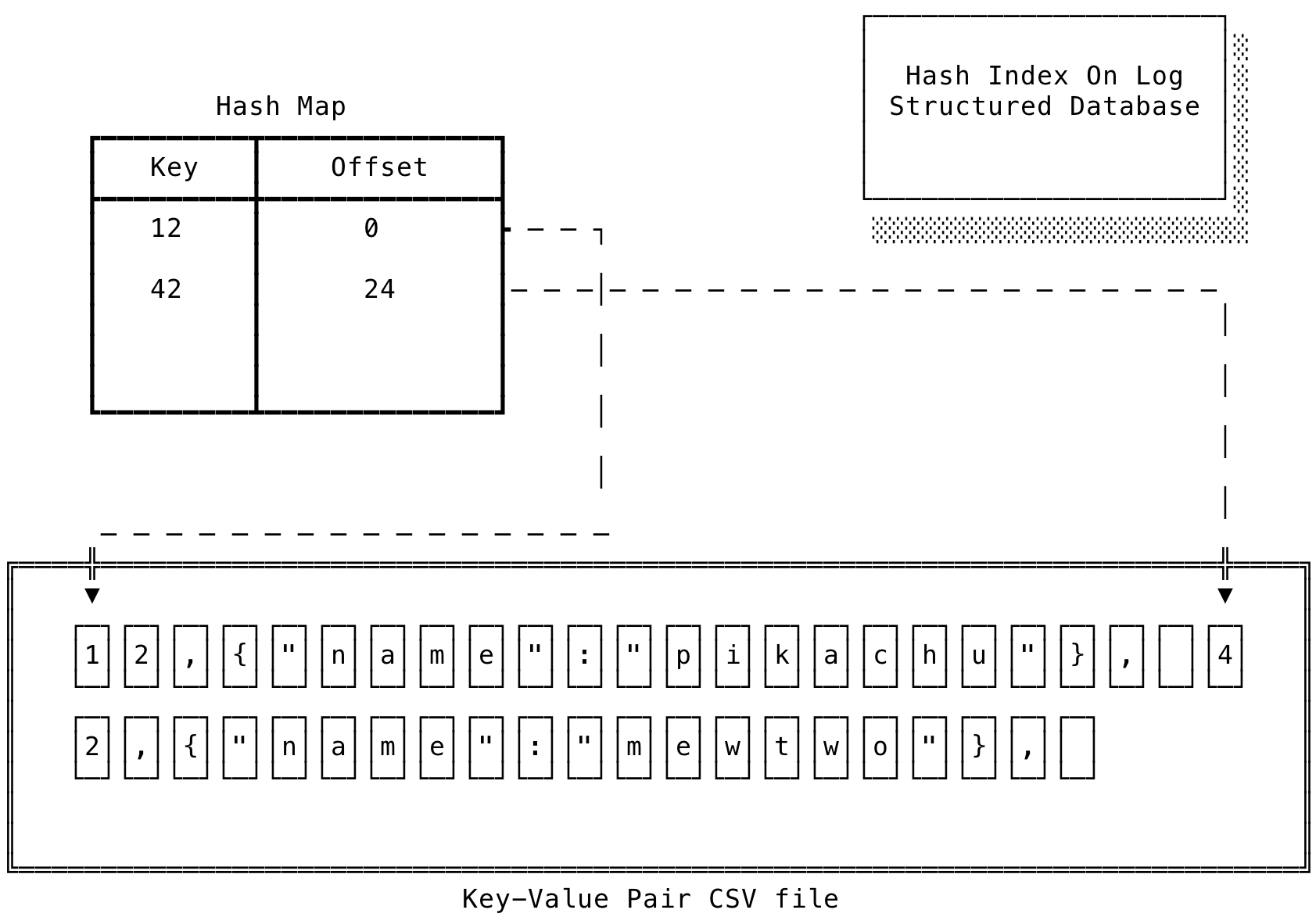
- Whenever a key is inserted or updated, the Hash index is updated with the new offset.
- When you need to retrieve an entry from the database, look for the key in the hash index and jump to the offset in the database file to retrieve the value.
- Deleting is also easy, Put a deletion marker as value (Tombstone) and assume the key is deleted if the value is a tombstone.
In case of a crash or sudden shutdown, the Hash Index can be created again by reading the database file sequentially.
As with all inserts and updates, the database file is appended and grows bigger, with this you will eventually run out of space. To prevent that from happening compaction is used.
Compaction
Compaction is a simple process of keeping the most recent value of a key and discarding the rest.
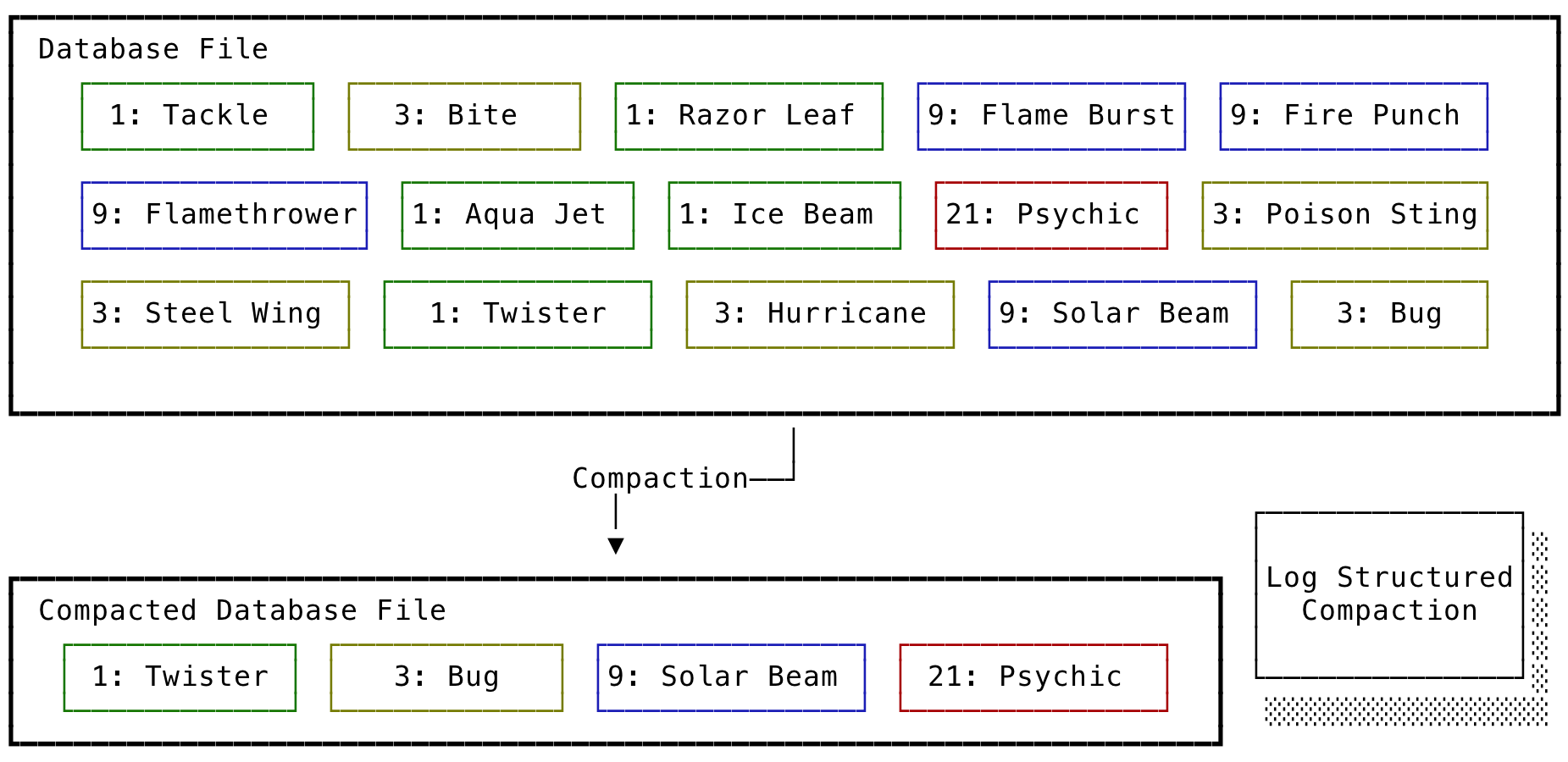
Typically a database file is broken into multiple files called segments which has a predefined capacity. When a segment reaches its maximum capacity, a new segment is created, and all new updates are redirected to the new segment.
These multiples of segments can be compacted into a new segment to save space and make queries faster.

When Compaction completes, we redirect read queries to new segments and old segments are deleted. Each segment has a Hash Index to serve its read requests which are also created during compaction.
Summary
Pros - Faster writes: Mostly does sequential write operation (append to segment and merge segments), which is faster than random writes (commonly) - Easier Read Concurrency: when segments reach maximum capacity and are closed, they become immutable and can serve concurrent reads.
Cons - In Memory: If your Key size is large and does not fit into main memory, then the Hash Index won’t help. Creating a performant on-disk hash index is hard to create and manage. - Range Queries: Only exact query matching is fast, for range queries you have to scan the whole Hash Index
Hash Index is used in storage engines such as Riak’s Bitcask.
Hash Indexes are suitable for heavy insert and update use cases (e.g., video view count), if keyspace fits in memory (less number of distinct keys), and you are mostly doing exact key match.
Thanks for reading!