Clockwork-Scheduler is a general-purpose distributed job scheduler. It offers you horizontally scalable scheduler with at least once delivery guarantees. It is fault-tolerant, persistent, easy to deploy and maintain.
Usage:
General-purpose scheduling by external services.
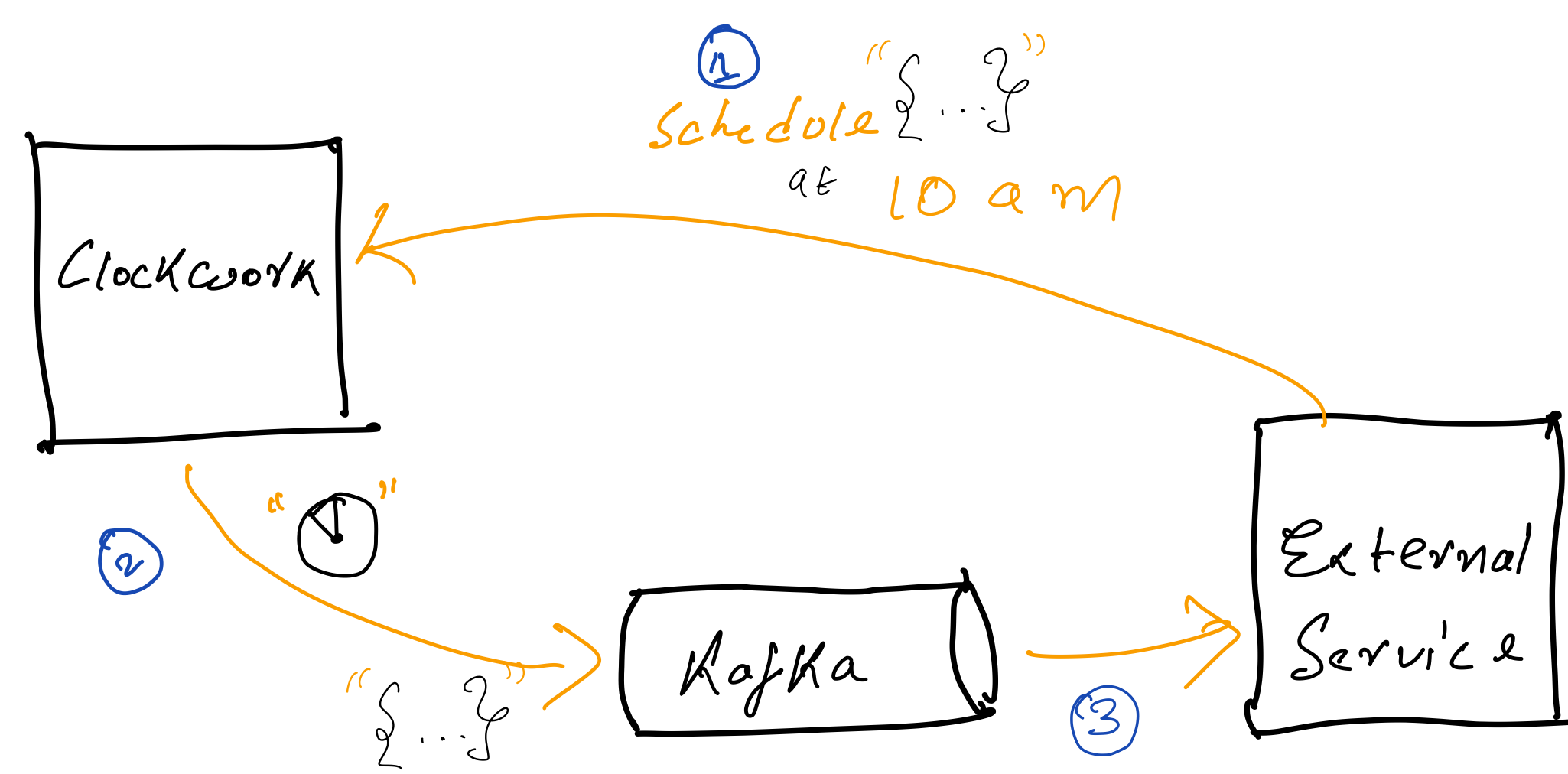
Clients can create Schedule at a specified time in the future, at scheduled time clockwork executes the schedule and delivers taskData to provided kafka topic. Right now only supported mode of delivery is kafka topic but plan to add more such as web hooks.
Existing Solutions
Architecture Approach and Challenges:
We started with a simple architecture of three components.
- Web API
- Database
- Schedule Execution workers
Schedule
{
"clientId": "client1",
"scheduleKey": "order1-create",
"taskData": "payload",
"delivery": {
"topic": "orderTopic"
},
"scheduleTime": 1553629195570
}
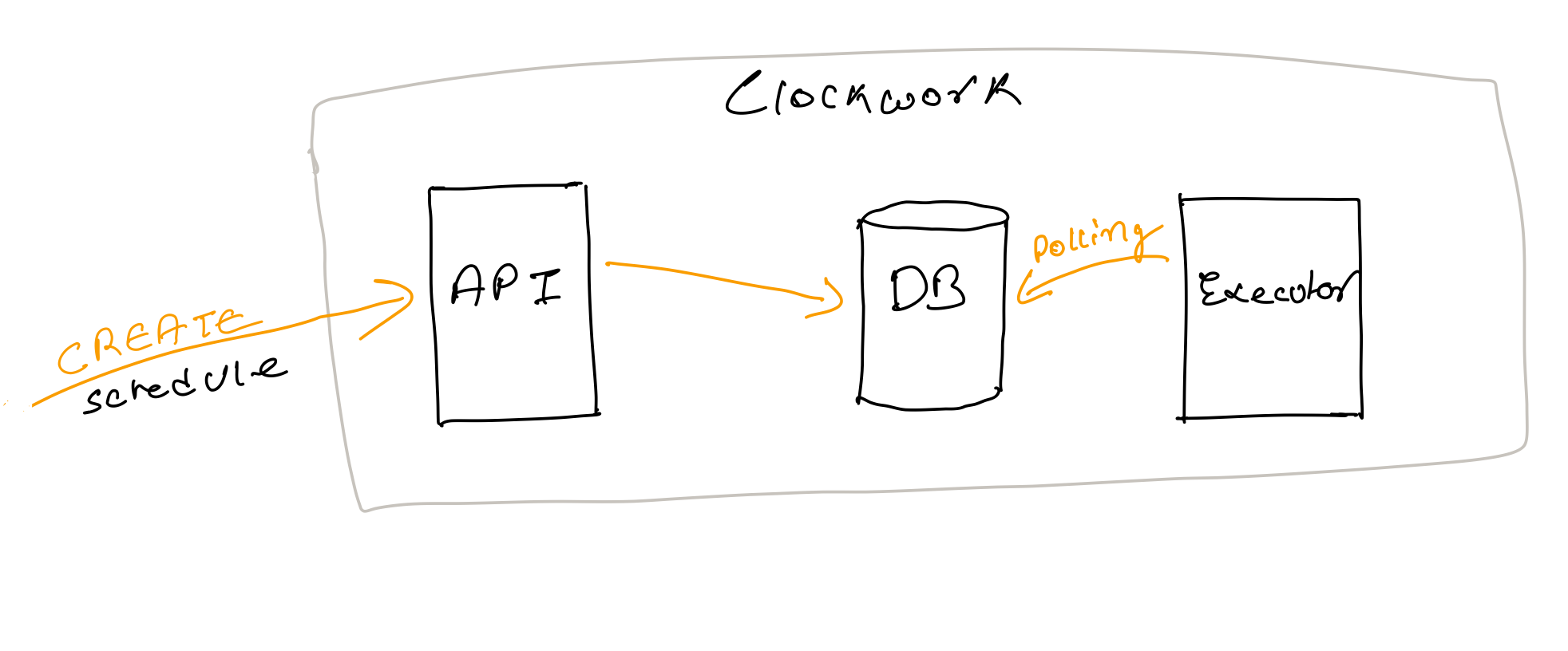
web api receives REST request to create schedules and puts it into the database. In the background an execution worker polling (scheduleTime < currentTime) on database, to find schedules to execute.
This approach has a major drawback, it won’t scale beyond one execution worker as all workers would try to execute the same schedules and there would be no performance gain.
Partition the Database
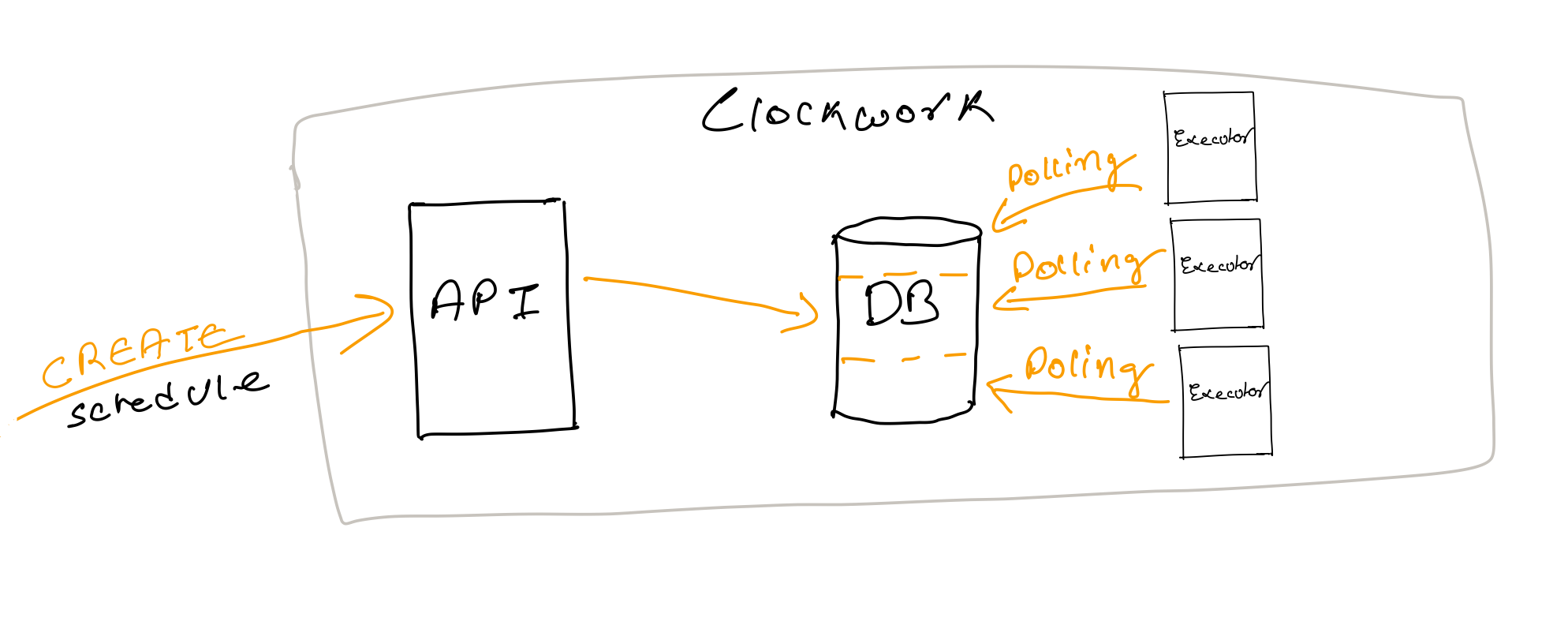
To solve this we can Partition or shard the database such that different execution workers can query on separate partitions and execute schedules in parallel.
We could use partitioned Postgres or MySQL but managing (adding new shards, backups, etc) such setup is challenging and we don’t need multi-document ACID guarantees. We could use distributed databases such as DynamoDB or Cassandra as which has partition support by default and maintaining their clusters is easier. We opted for DynamoDB as it is a fully managed service.
DynamoDB Basics
If you are already familiar with DynamoDB please skip this section. Each Document in DynamoDB must have a partition Key or hash key which determines which partition this document will go to, In addition to that, it can optionally define sort key which determines in what orders records in partitions, All data in one partition is sorted by provided sort key.
To find any document in Dynamodb we must provide the partition Key the document.
To learn more please check https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Introduction.html
Polling Query
partitionKey: ?
sortKey: scheduleKey
query: scheduleKey < currentTime
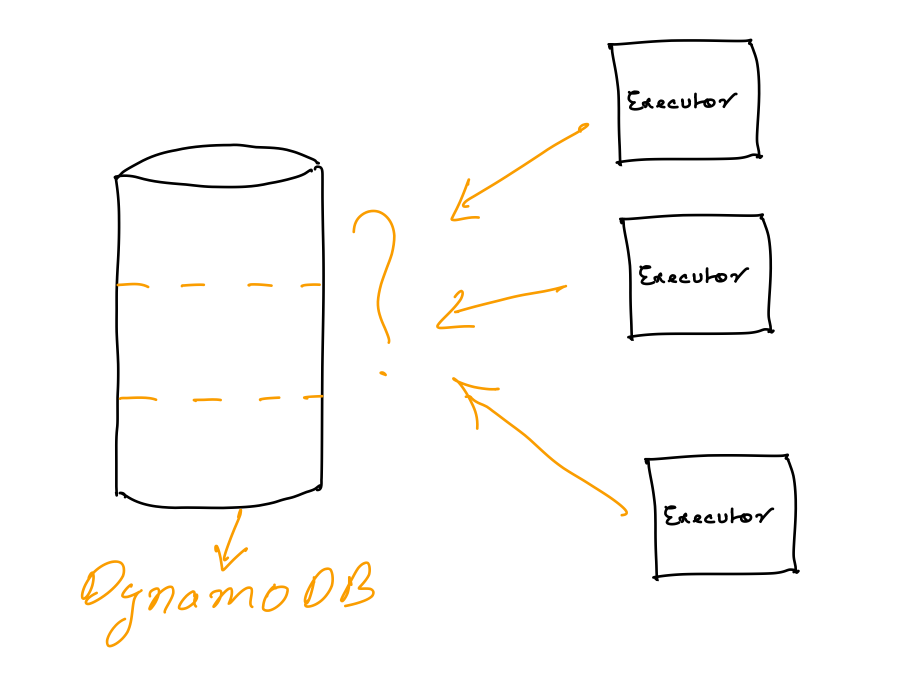
Choosing Partition Key
ScheduleId as partitionKey
We can choose Schedule Id as partition key as it is unique and random and will be evenly distributed across all Dynamo partitions. But as we cannot not know all possible scheduleKeys we cannot query on partitions without scheduleKey
ClientId as PartitionKey
We already know all clientId and can partition dataset on that. We can run one schedule executor worker for every clientId. This approach could work well but has a serious flaw, if one client is creating more schedule than one executor worker can handle then the executor will lag behind and breach our SLA, and if this is continued worker might never catch up.
Generating PartitionKey From ScheduleId
we can map scheduleId to a predefined range of values using consistent hashing algorithm and use generated value as partitionKey. It could be as simple as
scheduleId % no_of_partition. Check for more on consistent hashing https://en.wikipedia.org/wiki/Consistent_hashing
Coordinating Executor workers
Now that we know all partitionKeys, but we still need to figure out
- How would we assign one execution worker per partition?
- if any executor goes down how will we assign it’s partition to any other worker?
- How can we increase the number of executors with an increase in the number of executors at runtime?
Solution: Kafka
We are in luck, All the above tasks are performed by kafka internally to manage it’s consumers, and as we are already using kafka for delivery we can leverage kafka to perform all those tasks.
Brief About Kafka
Kafka is a distributed log or event store which can also be used as pub-sub and handle huge amount of traffic.
Kafka has topics and topics has partitions. Kafka uses consistent hashing to uniformly distribute load across all its partitions. Kafka uses consumer groups to assign consumers and reassign partitions to the consumer in case of consumer failure. https://kafka.apache.org/090/documentation.html#introduction
Leveraging Kafka
We can use kafka partitioning (consistent hashing) to generate partitionIds and consumer assignment to assign executor.

Every node of clockwork has kafka create consumers and schedule execution workers.
Both workers are in sync using kafka.
eg. if create worker is consuming form some partition lets say 3 then execution worker on the node will be polling on the same dynamo partition (3).
If kafka partition rebalances and same create worker is now listening to partition 1 then the execution worker will also be polling partition 1 of dynamo to execute jobs.
To scale out we can increase number of partition in kafka topic and add more clockwork nodes. Kafka will automatically assign new partitions to create workers execution workers on nodes will start polling new partitions.
Find the project on github https://github.com/uttpal/clockwork
Follow the discussion on Hacker News https://news.ycombinator.com/item?id=21173441